Summary (tldr;)
SplitSound is async by design on AWS: presigned multipart uploads to S3, job state in RDS, handoff through SQS Standard, ffmpeg and separation in an ECS worker. The API is the control plane; it never carries media bytes or waits on GPU work.
Part 1 defined the product. Part 2 locked entities, APIs, and scale assumptions. This post is the AWS architecture as I implemented it: which service owns what, how traffic flows, and why I split responsibilities the way I did, not because AWS has a checklist of services, but because separation work has a different shape than CRUD.
The architecture in one sentence
Separate the control plane from the media plane and the compute plane.
That line is the spine of high_level_system_design.md in the SplitSound repo, and it is how the Terraform modules are laid out. The reason is practical: each plane fails for different reasons and scales on different knobs. Mixing them turns every outage into “the API is slow” when the real problem might be queue backlog, a stuck ffmpeg job, or a full disk on a worker task.
| Plane | Responsibility | AWS (and friends) | Why split it out |
|---|---|---|---|
| Control | Auth, credits, job lifecycle, presigned URLs | ECS (FastAPI), RDS Postgres, ALB | Must stay fast and stateless; scales with HTTP traffic, not GPU minutes |
| Media | Original uploads and separated outputs | S3 (private bucket, per-user prefixes) | Bytes are large and cheap to store; should not pin API memory or Postgres size |
| Compute | ffmpeg, inference, writing stems back | ECS worker, SQS, outbound to inference provider | Slow, bursty, expensive; scale on queue depth and concurrency, not request rate |
The frontend (Vercel) talks HTTPS to the API and presigned S3 URLs only. Stripe and OAuth sit outside AWS but hit the same API. Nothing in the browser gets long-lived AWS credentials. I did not want “clone the repo and you have our S3 keys” to be a plausible support ticket.
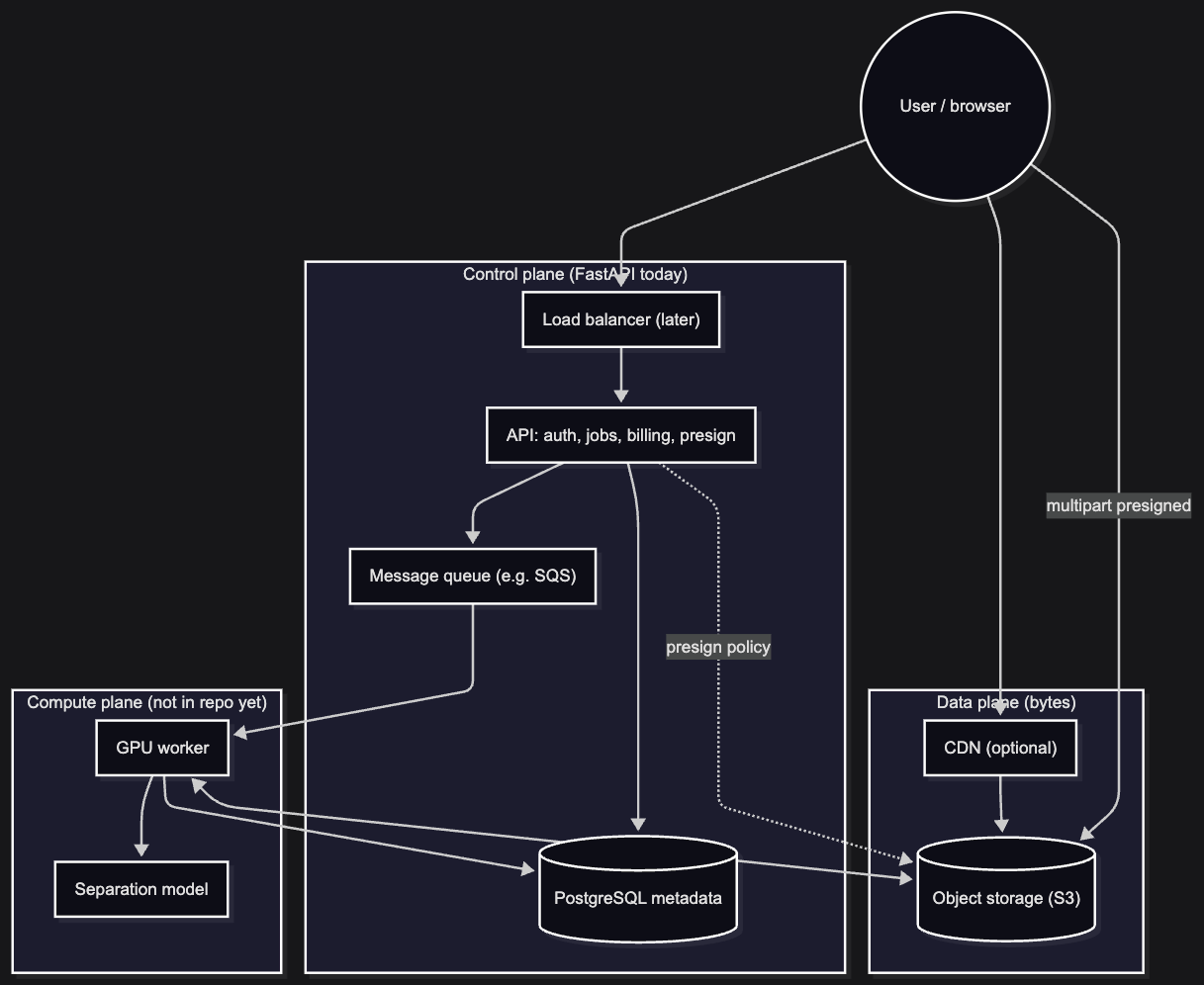
End-to-end topology
At a high level, these are the moving parts:
- Next.js on Vercel: upload UI, job polling, preview/download via URLs the API signs. Static hosting stays cheap and simple; all product logic that touches money or jobs stays behind the API.
- Application Load Balancer → ECS service (API): FastAPI,
/v1/*, admin routes, Stripe webhooks. ALB gives TLS termination and health checks without baking certificates into the container lifecycle. - RDS PostgreSQL: users,
CreditAccount,MediaAsset,SeparationJob,OutputTrack,UsageLog. Relational data because jobs, credits, and library views are joins and constraints, not blob storage. - S3: one media bucket; deterministic keys (
user_{id}/originals/...,user_{id}/jobs/job_{id}/output/...). One bucket keeps IAM and lifecycle rules manageable; per-user prefixes keep isolation enforceable in policy. - SQS Standard: job queue between API commit and worker pickup. A queue decouples “user clicked separate” from “a worker is free right now,” which is the whole product.
- ECS worker: long-polling SQS, read/write S3, update RDS; CPU task for MVP (inference via Replicate), with a GPU ECS track kept in Terraform for self-hosted SAM-Audio later.
- CloudWatch: logs and alarms on API and worker tasks. When something fails at 2 a.m., I need worker stage logs separate from API access logs.
Why a modular monolith, not microservices: I did not want fifteen deployables, fifteen IAM edges, and fifteen ways for a schema change to desync before the product has traffic. The API is one codebase with clear modules (auth, uploads, jobs, billing). The worker is a separate process because its scaling signal is queue depth and GPU concurrency, not ALB RPS; forcing them into one scaling policy would either over-provision API or starve jobs.
Note (What limits scale)
SplitSound is GPU-concurrency bound, not API RPS bound. I sized from “how many separations can run at once” and dollars per GPU-hour, not from load-test fantasies on GET /health. That mindset is why SQS and worker capacity matter more than adding Fargate tasks behind the ALB.
Data ownership (what lives where)
Postgres = state (users, credits, jobs, output rows, audit logs). S3 = bytes (originals and stems). SQS = in-flight wake-up messages only. The worker reloads truth from RDS.
That split avoids huge DB backups, loses admin queries if status lived only on the queue, and keeps the API from becoming a job poller under load.
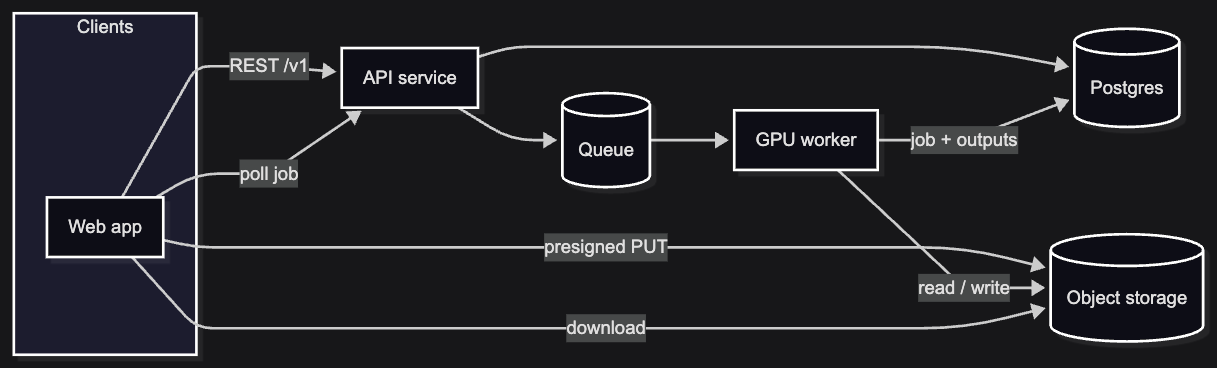
Flow 1: Upload (browser → S3, API as gatekeeper)
No file bytes through the API. Multipart presigned upload to S3 so parts can retry on bad networks and ECS tasks stay small.
Browser → initialize upload → API → S3 (multipart)Browser → PUT parts → S3Browser → complete upload → API → RDS (MediaAsset row)The API only creates the DB row after S3 confirms the object. Presigned URLs replace AWS keys in the browser; CORS must match the Vercel origin.
Flow 2: Job accept (API → RDS → SQS)
The API returns a job_id immediately; separation runs elsewhere.
Browser → POST /v1/jobs → API → RDS (credits + job row)API → SQS → 201 job_idBrowser → poll GET /v1/jobs/{id} → RDSCommit, then enqueue: debit and insert happen in one transaction; SendMessage runs after commit. If the queue call fails, the job is marked failed rather than stuck “processing” with no worker wake-up. SQS Standard (not FIFO): throughput and at-least-once delivery; the worker dedupes on DB state. Polling (not WebSockets in v1): job updates are minute-scale, and polling keeps ops simple.
Flow 3: Worker (SQS → S3 → inference → S3 → RDS)
python -m app.worker.main on ECS, the compute plane. Same stages whether inference is Replicate or a future in-VPC GPU; only the model step changes.
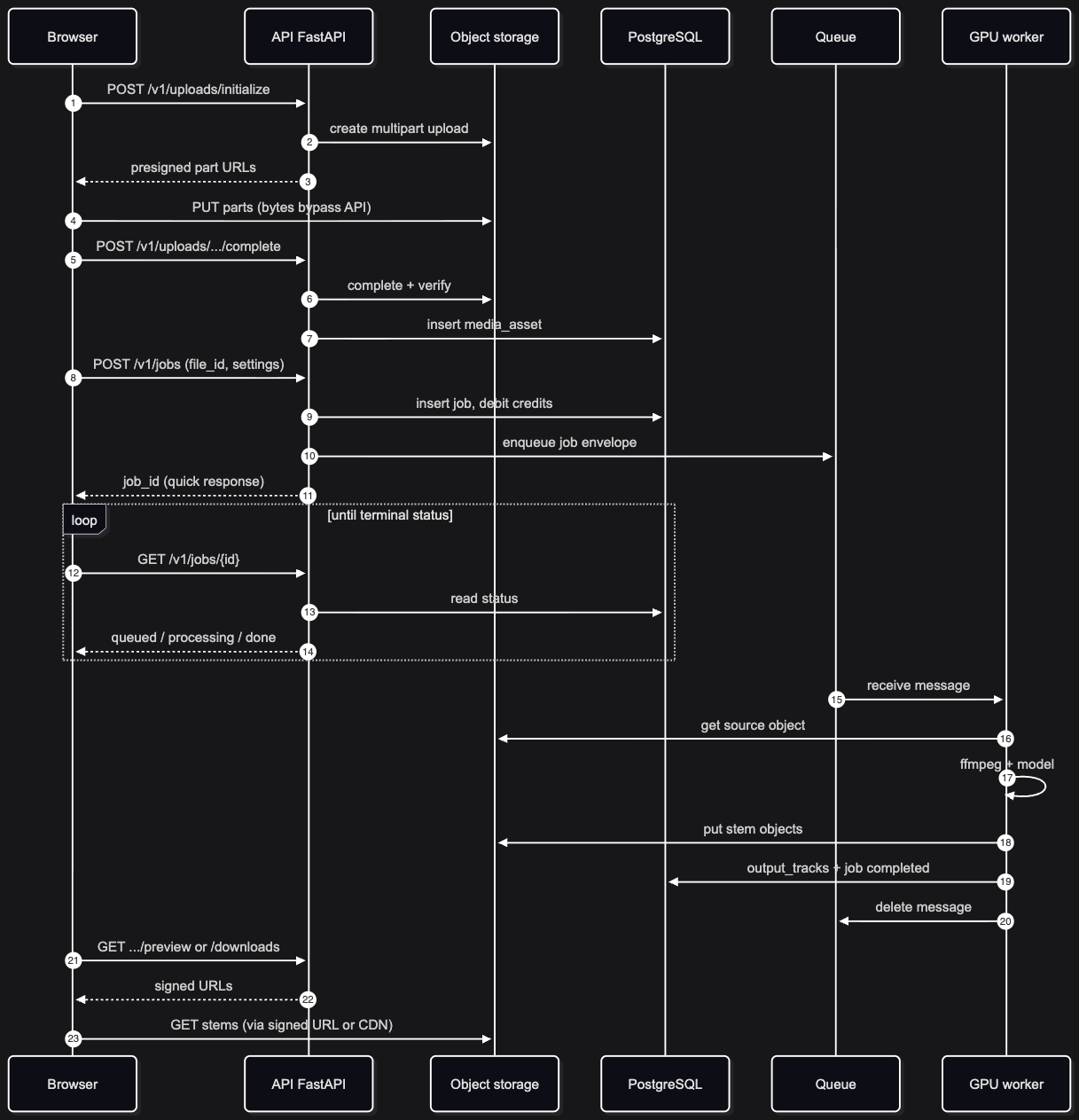
SQS → RDS + S3 download → ffmpeg → inference → S3 upload → RDS (outputs + status) → delete messageStages are separate so ffmpeg vs model failures get different retries, cancel checks land between steps, and support can read structured failure codes in RDS. The SQS message deletes only after success; idempotent keys handle at-least-once redelivery.
Today: CPU worker on ECS, inference via Replicate (WorkerModelAdapter, ADR 001) for margin and ops simplicity at low volume. The GPU ECS path stays in Terraform for when in-account SAM-Audio wins on cost.
Flow 4: Preview and download (API signs, browser fetches S3)
The API checks ownership and returns a presigned GET; the browser fetches S3 directly. No proxying bytes through ECS: private bucket, short-lived URLs.
Security and IAM (how AWS credentials are used)
Least privilege is not a slogan here; it is how I keep the frontend from becoming a credential leak.
| Actor | AWS access | Why |
|---|---|---|
| Browser | Presigned S3 PUT/GET only | No AWS keys in the bundle; scope is one object operation and a timeout |
| API task role | Multipart orchestration, presign, sqs:SendMessage, optional sqs:GetQueueAttributes | API enqueues work and signs URLs; it does not need to read every object on every request |
| Worker task role | sqs:ReceiveMessage, DeleteMessage, ChangeMessageVisibility, S3 read/write for job paths | Worker touches bytes and drains the queue; no need to create checkout sessions or presign for other users’ jobs |
| RDS | API and worker via secrets | Shared schema, different processes; credentials in Secrets Manager / task secrets, not in images |
Admin routes (/v1/admin/*) use application-level elevation (ADMIN_EMAILS_CSV + JWT claim), not a second AWS operator identity for day-to-day support. Ops needs queue depth and job rows in Postgres, not the production root key.
Lesson baked into the runbooks: SendMessage (enqueue) and GetQueueAttributes (dashboard queue depth) are different IAM actions. I fixed enqueue and wondered why the admin panel still said 503 until I extended the API role for metrics.
How I deploy it (Terraform modules)
I split Terraform so I can stand up networking and data stores before the ALB exists, and so a bad API change does not require touching the bucket module.
| Module | What it provisions | Why separate |
|---|---|---|
infra/terraform/rds-vpc | VPC, subnets, RDS Postgres | Network and DB lifecycle are slow, sensitive, and shared |
infra/terraform/s3-sqs-ecs | Media bucket, job queue, task IAM | Data plane + queue + roles are the contract between API and worker |
infra/terraform/api-ecs | Fargate API service, ALB, ACM, secrets, CloudWatch | HTTP edge changes more often than the bucket layout |
infra/terraform/worker-ecs-gpu | GPU capacity provider + worker when self-hosted inference ships | GPU capacity is optional and expensive; should not block API deploys |
MVP can run API and worker as two ECS services, or as sidecar containers in one task (ADR 001): same image, different command, one desired count to operate early. I accept coupled restarts in that mode in exchange for fewer knobs. The boundaries (S3, SQS, RDS, worker stages) do not move.
Frontend env must point at the ALB URL; OAuth redirect URIs and S3 CORS must match that hostname.
Control in ECS + RDS, bytes in S3, patience in SQS, heavy work in the worker. When inference is slow, the API stays fast and I know which dial to turn when something breaks.